README
harddrive-party - peer-to-peer media index and file-sharing
Status: Pre-alpha - expect bugs and breaking changes
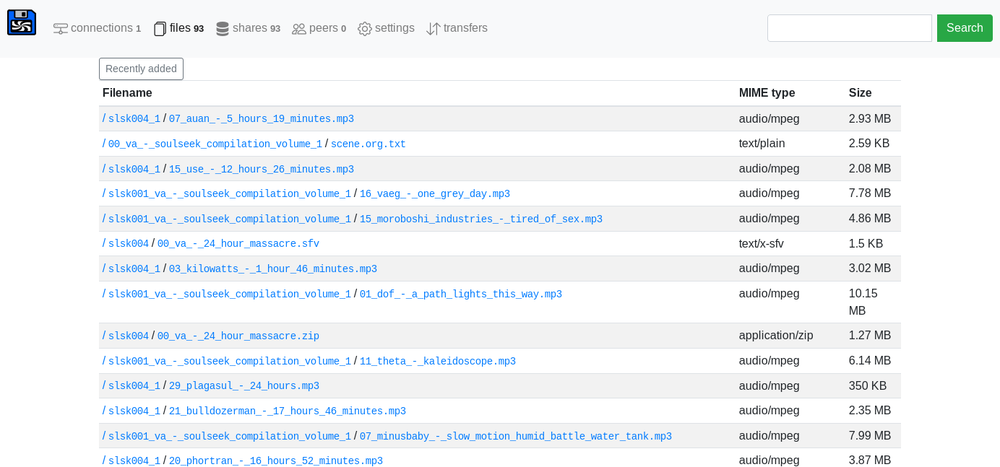
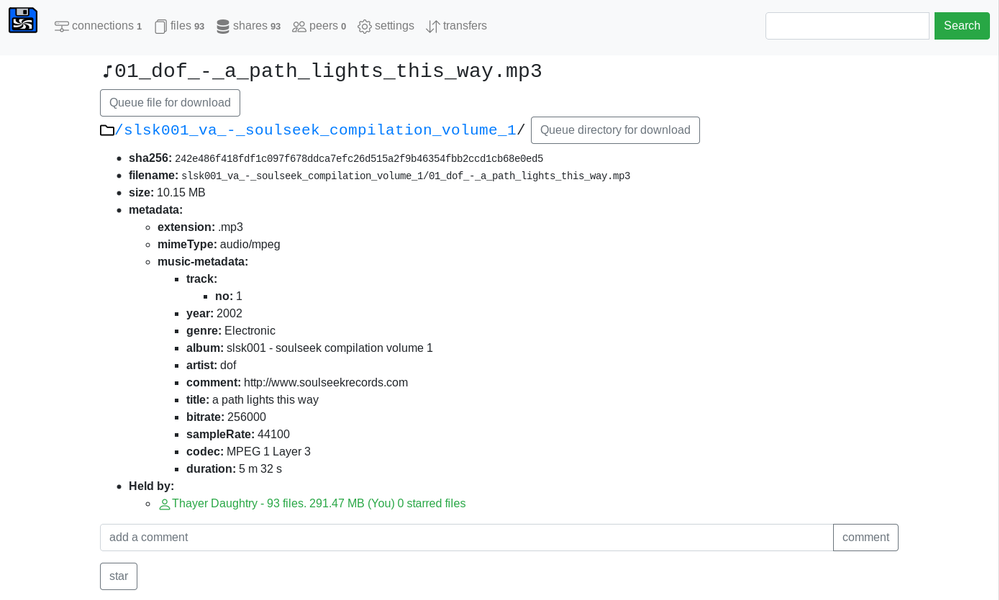
Harddrive-party is a peer-to-peer file-sharing application which uses a distributed media file metadata index, metadb. Peers create an index by extracting information about media files they want to share, and replicating this data with other peers, to create a searchable distributed database of all known files.
Peers find each other by 'meeting' at a private or semi-private 'party' by using a common swarm name on a distributed hash table. There is no public, open network - in order to connect to another peer, you either need to know their public key, or both be connected to a 'swarm' with the same name. This might be something obvious, like 'techno', or it could be a very difficult to guess random string.
metadb aims to be transport agnostic - a simple encrypted file transfer system is used by default, but it is also possible to include links for other protocols in the index, for example Gnutella, IPFS, DAT, Bittorrent, or HTTP.
It also aims to be extendible - arbitrary data can be published about files, such as comments, reviews, 'stars', links to web resources, and integration with local media libraries such as calibre or music player daemon could be possible in the future.
Why another file-sharing protocol?
There are many great peer-to-peer systems for publishing and downloading files, but not so many of them provide a distributed index. In some cases files get shared only with specific individuals, and in other cases they are listed on a centralised index which relies on servers.
Some projects, like Gnutella, provide a peer-to-peer mechanism for searching for files, but the difference here is that the entire index is transferred up-front, rather than specific requests propagating over the network. This means that searches are fast, and the index can be browsed when offline.
Another difference is that metadb has a system of private and semi-private groups, which can overlap. You can only transfer files with a peer you are actually connected to. But it is possible to 'gossip' indexes over indirect connections, providing you know a peer's public key. So the indexes of a wider community of peers than you are currently connected to.
The hope is that having semi-private communities will bring a sense of responsibility and accountability whilst still allowing new peers to discover content. There is also a possibility to have more closed groups, as well as allow-lists and block-lists for specific peers.
Its a bit like:
- Soulseek - in that you can browse files offered by a specific peer. But although there are some open-source clients, Soulseek uses a closed-source protocol and relies on a server for indexing.
- muWire - a great file-sharing platform which uses i2p for anonymity.
- Bitzi - was a collaborative online database with metadata about media files, with integration with several (then) popular filesharing platforms. archived version of bitzi website, wikipedia article
Features
- Remote control. It has an HTTP API and a simple web interface, meaning it can also be run on an ARM device, NAS, or other remote machine. Supports https and http basic auth.
- Offline first - the index is stored locally and swarms can be connected to over multicast DNS as well as the DHT, so it works over a local network (great for LAN parties).
- Remote queueing - requests are stored locally until connecting to a peer who has the requested files. They are then queued remotely until a download slot becomes free.
- Database built on kappa-core
- Pluggable metadata extractors add information about files to the index such as id3 tags and text previews. See metadata-extract.
How does it work?
It is largely based on the DAT/hyper stack with a few peculiarities.
Peers meet through joining a topic on the hyperswarm DHT, which could be the hash of a commonly known word or phrase, or a key chosen a random. The topic key is hashed (giving the 'discovery key') and knowledge of the original key is proved in a handshake, which also establishes the key used to sign entries to the peer's list of files - which is a hypercore append-only log.
Each connection between two peers comprises of two encrypted streams, one for replicating indexes using multifeed, and one for transferring files using a custom made protocol.
Since it is mostly based on the hyper stack, you might wonder why files are not transferred using hyperdrive. As of hyperdrive 10, it is difficult to include files in a hyperdrive which are actually stored as normal files on disk. Metadb is designed for sharing large media collections, and requiring people to either duplicate their collection or access them through a hyperdrive seems too restrictive. This might change though.
You might also wonder why a custom made handshake is used and not NOISE. We want to establish a signing key, and noise is based only on diffie-hellman. But it is possible to add a custom payload to a noise handshake, and perhaps thats what will happen, especially if people want the reassurance of using an established protocol, but for now this uses a custom handshake.
This module
This module is an http API exposing the functionality from metadb-core, and the web based front end, metadb-ui. A simple command-line interface is also included.
Installation and usage
- Install globally with npm or yarn, eg:
npm i -g harddrive-party(built with node version 11.15.0) - Run
harddrive-party start - You should see a link to the web interface served on
localhost. The default port is2323. - To get started, you probably want to index some media files, by clicking 'shares' in the web interface, or typing
harddrive-party index <directory>in another terminal window. - To connect to other users and merge databases, you need to connect to a swarm, on the 'connection' page. Here you can type a name which will be hashed to give a topic on the DHT to find other peers. There are currently no known public swarms.
- You can request files of other peers. Active transfers are not yet displayed in the interface very well, you should be able to see some output in the terminal window running to API.
If you want the process to run indefinitely, you can create a systemd service, or run with pm2 or forever.
Setting up a remote instance
- Start with your host name or IP address:
harddrive-party start --host 1.2.3.4 - If you want to use https you will needs key and certificate files, which you can create like this:
openssl req -nodes -new -x509 -keyout server.key -out server.cert- then start with options
--httpsKey server.key --httpsCert server.cert - if you want to set a username and password for http basic auth, use options
--basicAuthUser username --basicAuthPassword password - You can also set these options permanently in the config file, which by default is at
~/.metadb/config.yml. For example to set the host, add the line:host: 1.2.3.4
Development
Clone the repository, install with yarn or npm i, and run with:
DEBUG=metadb* ./cli.js start --test.
This will log debugging information and put downloaded files in the configuration directory.
To clear all application data and start fresh:
rm -rf ~/.metadb
Roadmap
- Commenting and stars - write comments about particular files - back end implemented, front end partially implemented.
- Wall messages - encrypted messages only viewable by people who know a swarm key - giving a 'message board' for each swarm. Partially implemented.
- Fulltext search. Search function currently uses a substring search of filepaths only
- Private messages and invites - send encrypted messages to a particular peer or invite a particular peer to another swarm. Implemented at protocol level only.
metadb is based on an older unfinished python project, meta-database.
