README

Version 1.0.1
Cette version permet de générer des mentions légales classique, sans correction de texte, inspiré de la plupart des générateurs classique. Dans d'autres versions, il y aura un gros travail sur le fond avec plusieurs ajouts, notament plusieurs langues disponible.
Donation crypto BAT

Wallet BAT : 0x13CE1CB9E7626B0201c9DC786569fce22bd4fa78
Guide d'utilisation du projet

Avant l'utilisation du projet il faut mettre la dernière version de NODE et de NPM sur le terminal.
(Attention à régler vos privilèges utilisateur sur votre système pour l'installation), Vous pouvez maintenant installer le paquet de façon générale, afin d'utiliser le binaire sur votre système avec la commande :
npm i -g legalwork
Une fois l'installation terminée, créer un nouveau dossier à l'endroit de votre choix :
mkdir monProject
Vous pouvez maintenant générer les mentions légales de deux façons, soit avec des questions depuis le prompt avec la commande :
legalwork
Soit avec des arguments obligatoires à donner dans le prompt avec la commande :
legalwork init --domain mon_domaine --proprietaire monNom --status SARL --adresse 38_impasse_blabla_33000_BORDEAUX --nomCreateur moi --partiesPrenante toi_moi_vous --urlCreateur siteCreateur --responsablePublication nom --emailResponsablePublication email --nomWebmaster nom --emailTelephoneWebmaster email/tel --hebergeurSiteWeb site --adresseHebergeurSiteWeb adresse
Une fois les mentions légales générées, vous pouvez voir le fichier HTML dans le répertoir "src" de votre nouveau dossier projet.
Le résultat ressemble à :
├── init.log
├── main.js
├── main.ts
├── package.json
├── package-lock.json
├── src
│ └── mentions-legales.html
└── tsconfig.json
Cahier des charges fonctionnel
--
--
Cadre du projet
Context
À l'heure où les sites web, e-boutiques et applications mobiles sont omniprésents dans la vie des consommateurs, les besoins en conformité se font de plus en plus ressentir par les entreprises notamment depuis le RGPD début juin 2018.
Nous avons rencontré RABIER Géraldine, référente de la filière Digital Marketing et Communication de l'école de Ynov Bordeaux, qui est bien ancrée dans le milieu de notre projet. Elle nous a expliqué plus en détails les réalités du besoin des mentions légales.
En effet, les mentions légales son plein de subtilités puisque selon les réclamations des utilisateurs il peut y avoir plus ou moins d'impact sur le chiffre d'affaires d'une entreprise.
Nous avons donc eu l'idée de créer un générateur de mentions légales permettant de générer un document unique à partir de réponses d'un questionnaire que l'utilisateur remplit, dans un premier temps au format HTML utilisable par un développeur depuis par exemple son terminal en utilisant NPM, puis à l'avenir depuis une page web, et pourquoi pas dans d'autres versions consommer notre logiciel en tant que web service.
Aujourd'hui, il est intéressant voir important d'automatiser cette action, afin que toutes les personnes faisant la gestion d'un site web ou d'une application puissent avoir un document conforme sans contrainte et/ou risques liées aux possibles réclamations à venir. Cet outil que nous voulons développer pourra aider plus largement n'importe quel public intéressé à avoir des mentions légales.
Parties prenantes
Nous avons identifié les parties prenantes intégrant l'écosystème du projet. Il n'y a pas de rôle de donneur d'ordre, il y a une seule personne qui représentera l'équipe qui répondra aux besoins.
Afin de favoriser la viabilité et la résilience de cet écosystème, on sera attentif aux interlocuteurs et on s'efforcera durant le projet à :
Réduire l'urgence et les relations de hiérarchie en favorisant la collaboration ;
Communiquer un maximum sur la moindre problématique, question, évolution ;
Favoriser les échanges avec les parties prenantes ayant des compétences à partager ;
Mettre l'accent sur la visibilité du projet ;
Enjeux et objectifs
Lors d'une première réflexion sur le projet vendredi 6 mars 2020, nous avons convenu des points qui composeront le prototype présenté plus tard.
Notre générateur sera téléchargeable depuis la librairie NPM et utilisable depuis un terminal. Il y aura deux modes possible : le premier avec des questions depuis le prompt le second avec des arguments à donner, ceci permettant une fois les informations reçues par notre logiciel de générer les mentions légales au format HTML. L'enjeu dans cette première version, sera de rendre possible la génération des mentions légales incluant les CGU (Condition Général d'Utilisation) en étant conforme RGPD.
Dans le futur, d'autres versions de notre outil permettront d'avoir d'autres éléments tel que les CGV (Condition Général de Vente)... Nous pouvons penser également à une API RESTFul pour avoir un webservice consommable par d'autres utilisateurs.
Nous allons développer le projet en TDD, en y incluant le langage Typescript et les outils : Hygen et Mocha. Nous utiliserons Gitlab pour le versionning de notre code source, ainsi que l'Intégration Continue pour vérifier la qualité de notre projet par les tests unitaires.
Contraintes, limites et tolérances
Nous avons plusieurs contraintes à prendre en compte au niveau du logiciel à livrer. Celui-ci devra :
Respecter les normes et les lois, comme le RGPD (Règlement Général sur la Protection des Données) ou encore les règlements internes à l'entreprise.
Avoir des mises à jour courtes et compatibles.
Respecter les normes d'utilisation.
Être compatible sur n'importe quel matériel.
Être disponible sur n'importe quel matériel en ligne et hors ligne.
Nous avons une date limite à respecter pour la livraison du projet. Aussi, les tâches à effectuer pendant les semaines d'étude imparties durant l'élective représentent 2/3 jours de développement.
Nous n'autorisons pas de tolérance sur les délais. Le premier livrable sera le cahier des charges, le second sera un oral pour présenter le prototype.
Nous n'avons pas assez de semaines d'étude sur cette élective pour prétendre la livraison d'un logiciel complet avec possiblement toutes les évolutions. Nous nous limiterons au minimum à la première version avec le prototype pour la génération des mentions légales incluant la CGU au format HTML.
Concernant la qualité et le contenu du rendu, il devront être conformes à la charte graphique du projet. Ces normes devront être respectées sur tous les rendus.
Conception et modélisation
Analyse fonctionnelle
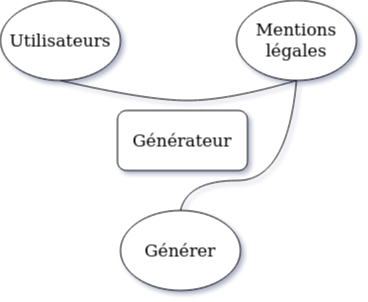
Pour déterminer l'expression du besoin de notre système, nous utilisons le diagramme de la bête à cornes.
On met au centre le système : le générateur.
En haut à gauche, il nous faut dire à qui le générateur rend service : les utilisateurs.
En haut à droite, il nous faut inscrire sur quoi le générateur agit : Les mentions légales.
En bas, il nous faut préciser dans quel but : générer des mentions légales.
L'expression de notre besoin est donc :
Le générateur permet à l'utilisateur de générer des mentions légales.
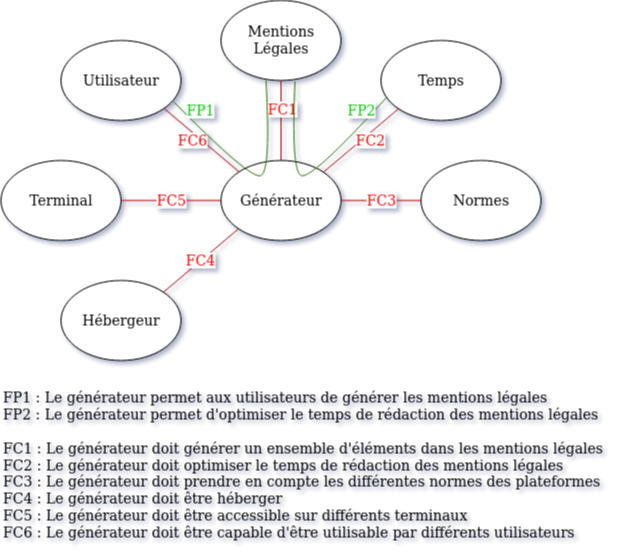
Diagramme de pieuvre
Pour déterminer les relations entre notre système et les éléments extérieurs à lui, on utilise le diagramme de pieuvre.
Au centre du diagramme, on met le système : le générateur.
Tout autour de notre système nous définissons les éléments extérieurs : l'hébergeur, le terminal etc.
Lorsque le système permet à un élément extérieur d'interagir avec un autre élément, c'est une fonction principale (FP) et on peut donc relier un élément extérieur au système puis à un autre élément extérieur.
Si le générateur doit être adapté à un élément extérieur, c'est une fonction de contrainte (FC) et on peut donc relier l'élément extérieur au système.
Voici le diagramme de pieuvre appliqué au projet Legal Work :
Architecture logicielle
Après de nombreuses recherches sur l'architecture micro-services, nous avons conclu que le projet n'est pas à vocation d'être un ERP (Enterprise Resource Planning) ou un CRM (Customer Relationship Management) qui nécessiterait d'isoler chaque service et de les rendre indépendants, nous n'avons pas non plus l'intention de faire du code spaghettis.
En effet, le projet à très peu de fonctionnalités répondant à très peu de cas d'usage, il a pour principal objectif de générer les mentions légales.
Au vu des compétences de l'équipe, du délai et du périmètre fonctionnel du logiciel, il nous semble pertinent de ne pas utiliser d'architecture, simplement un seul tiers front suffira.
Pour les évolutions, nous avons fait le choix d'intégrer plus tard l'interface REST, car le couplage des composants est inexistant donc plus facile à utiliser.
En effet, si nous développons à l'avenir des services RESTful, ils seront faciles à développer et à déployer : légers, avec un hébergement et une maintenance économiques, ils constituent la solution idéale pour de futures versions.
Il est très pratique et agile d'avoir une application RESTful, cela nous offre la possibilité d'ajouter un Framework Frontend qui peut communiquer depuis les services exposés par le Backend, tout en étant un frontal-tiers isolé hors du monolithe depuis un autre serveur.
Cela nous laisse également la possibilité de créer une application mobile qui peut communiquer avec nos services.
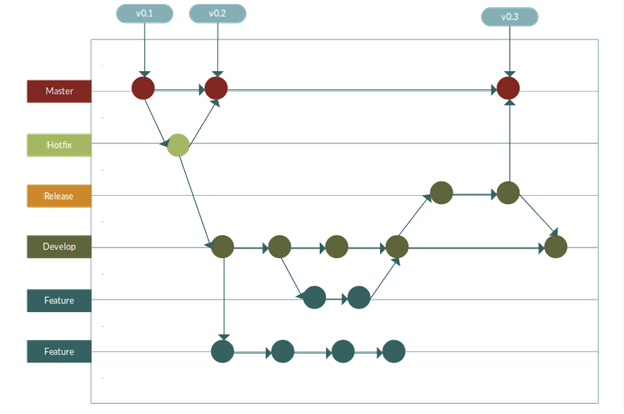
GITFLOW
GitFlow est une technique qui se base sur la création de branches. Ce workflow est facile à comprendre et évite beaucoup de conflits. Il permet aussi une meilleure visibilité et une meilleure gestion des développements.
Le diagramme couvre l'ensemble des besoins standards pour la plupart des projets de développement, cela fonctionne encore mieux dans une gestion Agile avec le cadre Scrum.
Il se lit de gauche à droite, la flèche qui part de la base indique que lorsqu'on créer une branche on doit partir de ce point.
Déploiement
Mise en recette et production
Note : l'argumentation est donnée à titre indicatif dans le cas où le prototype irait plus loin.
Pour la recette de notre application, nous avons imaginé avoir un serveur dédié contenant notre application sur un DNS par exemple (recette.monprojet.fr).
En version stable, la solution serait challengée par notre équipe et validée par notre client après la rétrospective de sprint dans le cas d'une équipe complète avec un client.
Il pourra grâce à cela nous remonter les éventuels écarts que nous aurions commis dans la réalisation des fonctionnalités demandées.
Pour la mise en production, nous pensons la faire sur NPM et ensuite, pour les prochaines versions, dans un container docker.
Celui-ci serait exécuté sur le serveur dédié sur un OS linux de la distribution Ubuntu, avec un DNS par exemple (monprojet.fr), nous pensons utiliser un reverse proxy avec en frontal Nginx et en back Apache. Sinon pourquoi pas l'externaliser chez AWS ou OVH.
Maintenance et évolutions
Note : l'argumentation est donnée à titre indicatif dans le cas où le prototype irait plus loin.
Pour réaliser une intégration continue de notre logiciel pendant les développements, nous utiliserons GitLab CI.
Dans le pipeline nous mettrons principalement une étape (builder le projet et lancer les tests unitaires), sinon nous pourrions dans d'autres versions faire plusieurs étapes :
Builder
Tester unitaire Back
Envoyer un rapport à SonarCloud
Créer l'image docker
Envoyer l'image au registry de gitlab
Pour la maintenance, nous utiliserons un outil de ticketing et Jira avec nos différents clients, permettant de suivre les changements.
Nous aurons un low-balancer et nous exécuterons notre logiciel sur plusieurs serveurs, permettant en cas de maintenance de rediriger le trafic sur une autre instance du logiciel.
Pour l'évolution du logiciel, nous avons pensé rendre souple l'architecture aux changements avec le REST, afin que l'évolution vers une architecture micro-services soit une possibilité si le besoin se présente.
**