README
yatta for arXiv and google-scholar
Yatta is like PIP or NPM for your papers. It is a cli tool that manages your paper bibliography data and PDFs. Think of PIP for your papers, and 100x better. :rocket::beer:Share Me on HackerNews!:fire::star:
- Do you ever wonder what is the right way to search arXiv?
- Have you ever wanted to save paper PDFs in your work folder?
- Have you ever had duplicates of the same PDF in different project folders?
- Have you ever wanted to share a list of readings with someone, except that your own PDFs all have personal notes and highlights?
yatta is the tool that solves all of these problems for you. It is a package manager for links and papers. It saves a index of bibliography data in a yatta.yml file in your work folder, so that if you want to share those papers, you can just send someone the index, and have them do yatta download.
We solve some of the annoying problems, so that you don't have to. Plus yatta is open source, so you can help shape the direction it goes!
Usage
First run npm install -g yatta. If you don't have node on your computer, first install it from here. Alternatively you can use brew install node on a mac.
Then, go to a folder where you want to save your readings:
mkdir my_awesome_deep_learning_project
cd my_awesome_deep_learning_project
yatta init
Now yatta should create a yatta.yml file for you. This is going to be the index file for yatta.
To search and download papers, do
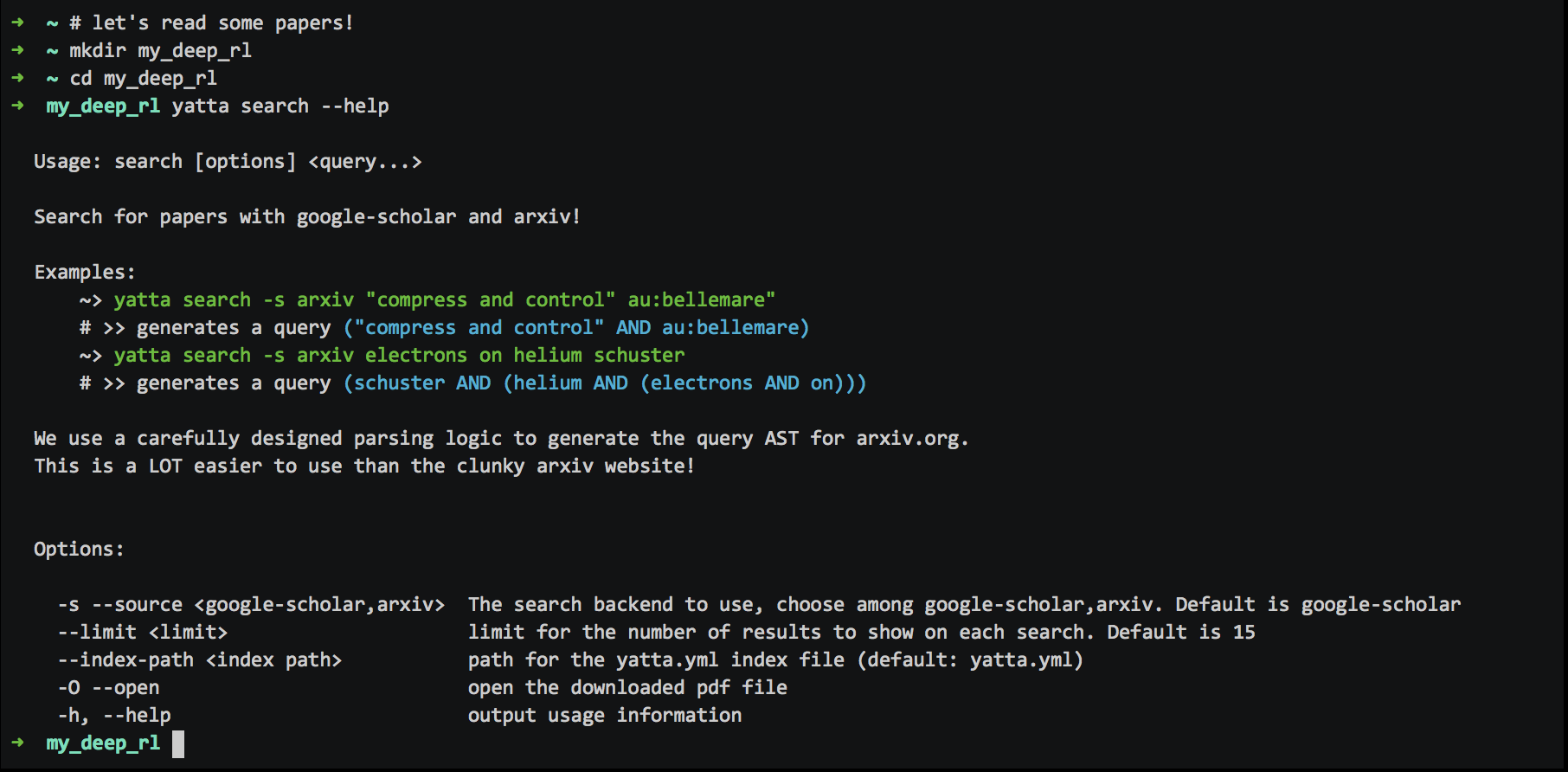
yatta search --source arxiv "Generative Adversarial Imitation Learning"
and it gives the following result: [placeholder image]
We support the FULL arxiv search query syntax!
for example for the following query, you get:
yatta search au:bellemare ti:compress and controll
Settings
you can run
yatta set dir <name of your target dir> # this sets where you are going to save the pdf files.
yatta set search.source <google-scholar or arxiv> # this sets the search engine to unse
yatta set search.limit <an integer> # this sets the number of return entries to show. Pagination support will come later.
yatta set search.open <true or false> # this sets the behavior after download: open the pdf up or not?
How to find help:
There are two ways to get help:
take a look at the help page of the command. You can do this by putting in:
yatta --help # or yatta <command> --help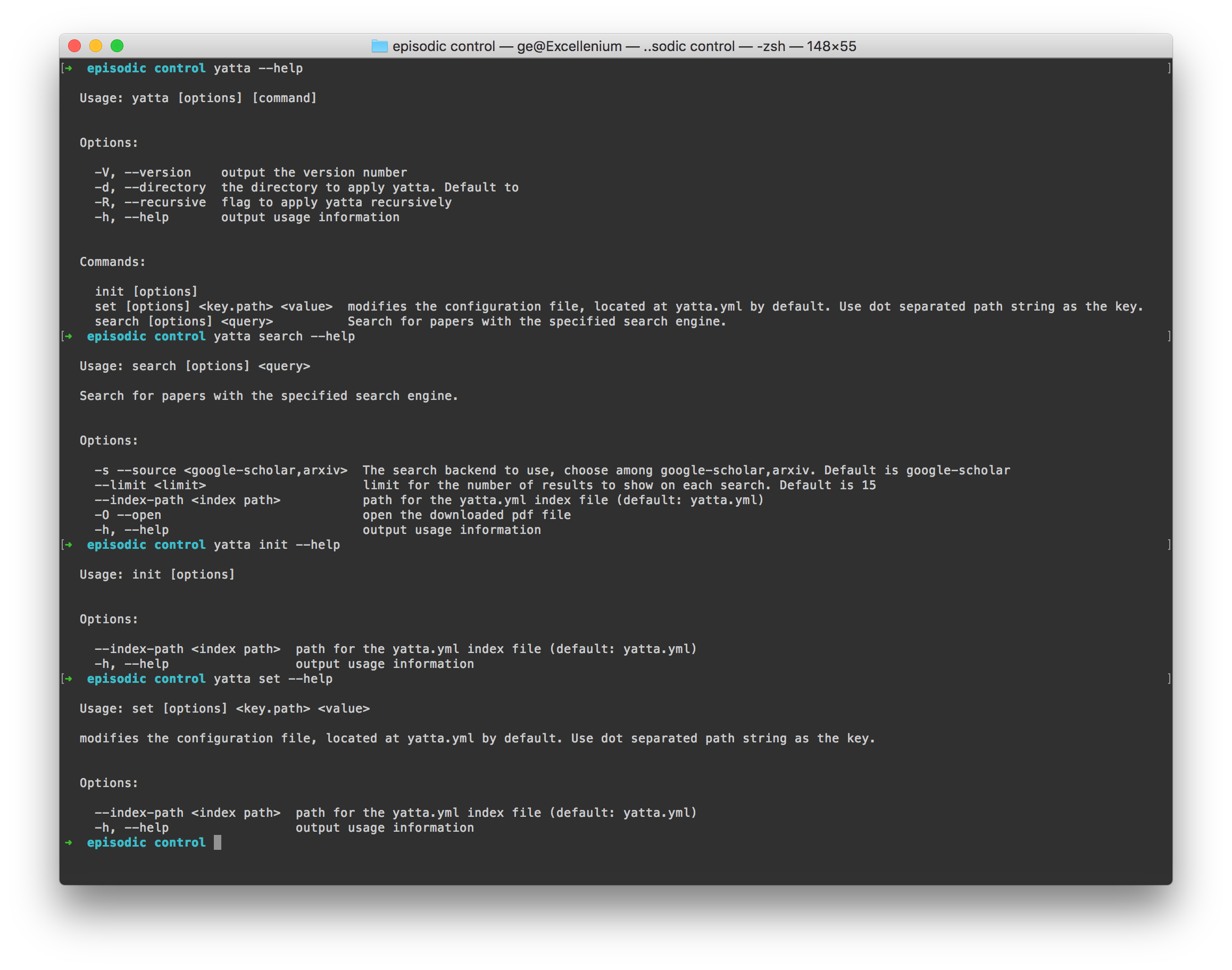
Alternatively, a quick look at the source would also be helpful: ./src/yatta.js.
To Develop
- Use
dev:installto install - Use
buildto update the local develop binary. You do NOT need to reinstall! - Use
dev:updateis deprecated.
Plans
Design
yatta searchdo NOT save index. index should be volatile.
save file content sginature + bib information instead.
yatta syncno.
Issues
- fix create alias step
yatta index: indeces files underrc.libdirectory and save as~/Dropbox/machine learning/library- [ ]library/index.yml: index of signatures and file paths - [ ]library/bib.yml: index of available yml files linked to the signatures- save bib info inside those PDF
- save aliases under yatta.dir
- save file signature
Todo:
- use rc.lib_dir instead
- save file under ~/Dropbox/machine learning/papers
- save setting under ~/.yattarc.yml
Done
- make a list of problems
2018-02-22
default behavior:
- first run, setup ~/.yatta.yml and ~/.yatta folder. folder contains
all,papers,searches,authorsetc. - save papers under papers, alias in searches folder.
- when searching under project folder, save alias/symbolic link under project folder. Problem, dropbox does not sync this.
Trade-offs:
- alias in project folder: dropbox does not sync. Pro: all papers safe in global folder.
- alias in global, save file in project directory: global is basically useless as archive now. Pro: could easily modify files and view them on dropbox. Easy to delete files assuming papers not found (through global alias) can be safely deleted.
- files in global, index in project, alias for convenience
- mobile:
- can view and edit files, can't see context. context is just bunch of dead links
- can browse local context inside
_papers, otherwise no.yatta shadowcreates this _papers folder from global, index etc.
- organizing files:
- in finder, drag and drop alias.
yatta syncindeces local files. Yaml index of location of files. This is useful forescherpadapp too.
- in finder, drag and drop alias.
- mobile:
Editing happens equally frequently from iPads and desktop.
2018-02-01
stuff to think about:
- managing papers is about organizing them. Make it easy to:
- search for papers
- organize papers into folders?
- remove useless papers?
I think if you do search well, everything else won't matter that much. So we could forget about
managingas long it is easy for other devices to view the papers. limiter: don't think of managing papers. Just put them under a folder for now. But make is easy to search under current scope.
TODOs
- Alternative is to use
arXivas the ultimate index. No need to save index. Just move the papers around. - use
node-exiftoolto insert meta data into the PDF after download. - save bib data together with the file? delete file, move file, link file, copy file, show what folder file is in
- save link to PDF in a global folder
- has a command line tool that converts link to a hard link (alternatively just use hard link)
stuff that actually need to be implemented:
file.getBib()need to be possible. Need a way to identify a single entry in the bib index (or 50 copies).yatta indexto generate a index of PDFs in current folder, or to generate the complete bibs.yatta bib -f blah-some-paper.pdffinds a few suggestions for the bibliography entry for this paper.
- Work through the UX, make sure things make sense.
- save a copy of PDF and
yatta.ymlindex under your home directory~/.yatta. - sym-link or hard-link files from
~/.yatta/papers/to your current directory. - Add search from
~/.yatta/yatta.mlto the results ofyatta search. - list
pdfsin local directory - list
pdfsin current index - add support for multiple options in current folder:
- download appropriate bib info for local file (arxiv id; pdf title; )
- save linked yatta bib in global bib
- open (from index, from local)
- edit bib
- edit filename
- delete bib
- add history to search terms (shall this be a
zshintegration?)