README
 zhlint
zhlint
{kind=link}
A linting tool for Chinese text content.
How to install
You could easily install zhlint through npm or yarn:
# install through npm
npm install zhlint -g
# or through yarn
yarn global add zhlint
Usage
As CLI
# glob files, lint them, and print validation report,
# and exit with code `1` if there is any error found.
zhlint <file-pattern>
# glob files and fix their all possilbly found errors.
zhlint <file-pattern> --fix
# lint the file and output fixed content into another file
zhlint <input-file-path> --output=<output-file-path>
# print usage info
zhlint --help
The validation report might look like this:

As Node.js package
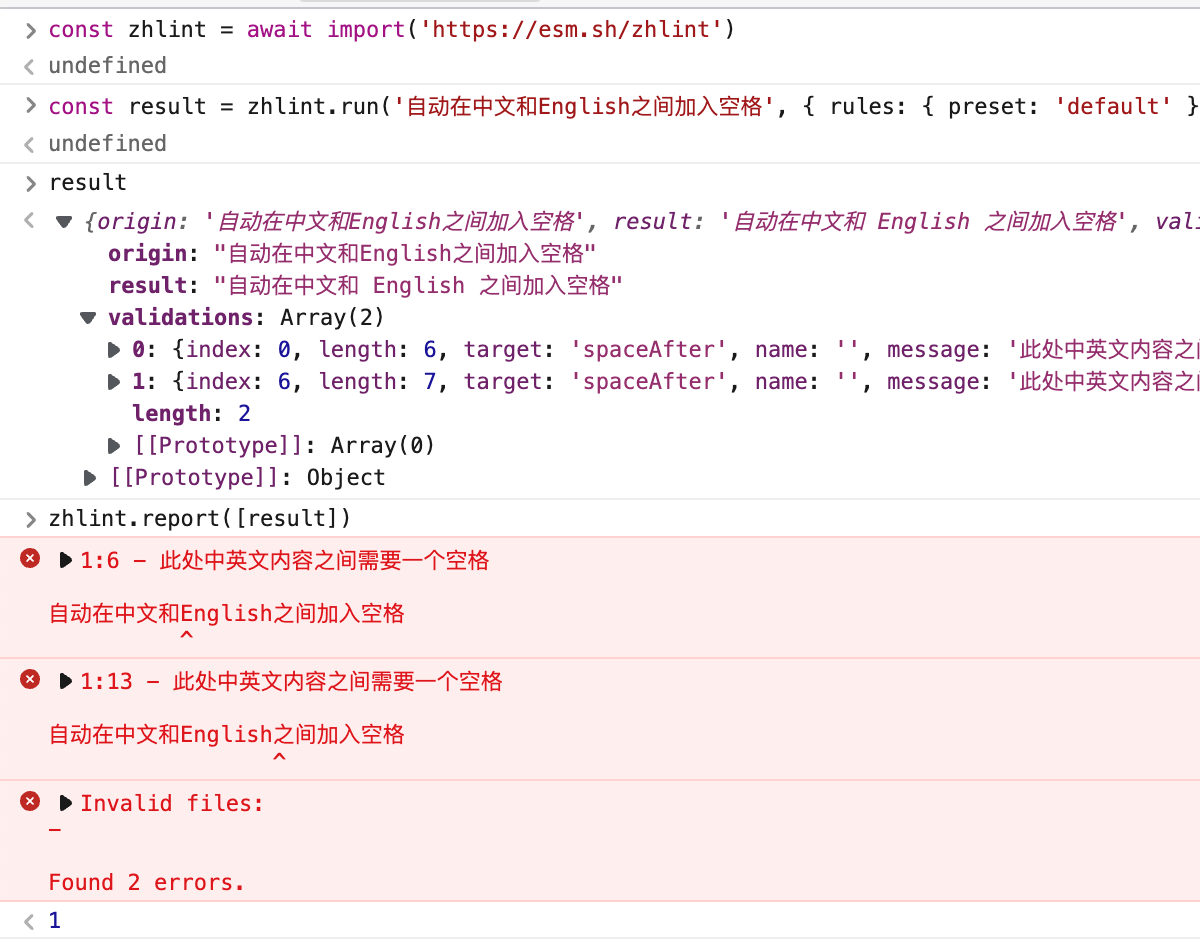
const { run, report } = require('zhlint')
const value = '自动在中文和English之间加入空格'
const output = run(value)
// print '自动在中文和 English 之间加入空格''
console.log(output.result)
// print validation report
report([output])
And the format of validation report is more like this:
1:6 - There should be a space between a half-width content and a full-width content
自动在中文和English之间加入空格
^
1:13 - There should be a space between a half-width content and a full-width content
自动在中文和English之间加入空格
^
Invalid files:
- foo.md
Found 2 errors.
As a standalone package
You could find a JavaScript file dist/zhlint.js as a standalone version. To use it, for example, you can directly add it into your browser as a <script> tag. Then there would be a global variable zhlint for you.
API
run(str: string, options?: Options): Result: Lint a certain file.- parameters:
str: The text content you want to lint.options: Some options for advanced usage.
- returns:
- The result of a single piece of input string. It contains fixed text content as
valueand the infor of allvalidations.
- The result of a single piece of input string. It contains fixed text content as
- parameters:
report(results: Result[], logger?: Console): void: Print out the validation reports for each file.- parameters:
results: An array for all linted results.logger: The logger instance, by default it'sconsolein Node.js/browser.
- parameters:
Other type defs and advanced usage
Result:{ file?: string, origin: string, result: string, validations: Validation[] }file: The file name. It's an optional field which is only used in CLI.origin: the original text content.result: the finally fixed text content.validations: All the validation information.
Validation:{ index: number, length: number, name: string, target: string, message: string }index: The index of the target token in the input string.length: The length of the target token in the input string.message: The description of this validation in natural language.
Options:{ rules?: string[], hyperParse?: string[], ignoredCases?: IgnoredCase[], logger?: Console }: Customize your own rules and other advanced options.rules: customize the linting rules by their names, could beundefinedwhich means just use the default rules.hyperParse: customize the hyper parser by their names, could beundefinedwhich means just use default ignored cases parser, Markdown parser and the Hexo tags parser.ignoredCases: provide exception cases which you would like to skip.logger: same to the parameter inreport(...).
IgnoredCase:{ prefix?, textStart, textEnd?, suffix? }- Just follows a certain format inspired from W3C Scroll To Text Fragment Proposal.
Features
Markdown syntax support
We support lint your text content in Markdown syntax by default. For example:
run('自动在_中文_和**English**之间加入空格')
It will analyse the Markdown syntax first and extract the pure text content and do the lint job. After that the fixed pure text content could be replaced back to the raw Markdown string and returned as the output value in result.
Hexo tags syntax support
Specially, we support Hexo tags syntax just because when we use Hexo to build Vue.js website, the markdown source files more or less include special tags like that so got the unpredictable result.
As a result, we additionally skip the Hexo-style tags by default. For example:
run('现在过滤器只能用在插入文本中 (`{% raw %}{{ }}{% endraw %}` tags)。')
Setup ignored cases
In some real cases we have special text contents not follow the rules by reason. So we could ues ignoredCases option to config that. For example we'd like to keep the spaces inside a pair of brackets, which is invalid by default. Then we could write one more line of HTML comment anywhere inside the file:
<!-- the good case -->
text before (text inside) text after
<!-- the bad case -->
vm.$on( event, callback )
<!-- then we could write this down below to make it work -->
<!-- zhlint ignore: ( , ) -->
or just pass it through as an option:
run(str, { ignoredCases: { textStart: '( ', textEnd: ' )' } })
Supported preproccessors (hyper parsers)
ignore: find all ignored pieces by the HTML comment<!-- zhlint ignore: ... -->hexo: find all Hexo tags to avoid them being parsed.markdown: parse by markdown syntax and find all block-level texts and inline-level marks.
Supported rules
Almost the rules come from the past translation experiences in W3C HTML Chinese interest group and Vue.js Chinese docsite.
... and this part might be controversial. So if you don't feel well at some point, we definitely would love to know and improve. Opening an issue is always welcome. Then we could discuss about the possible better option or decision.
mark-raw: keep one space out of the inline code in markdowntext`text`text->text `text` text
mark-hyper: move the space outside of the markdown markstext[ text ](link)text->text [text](link) text
unify-punctuation: unify all punctuations with same meaning, as part of the translation conventions, the punctuation should be full-width except brackets.中文, 中文.->中文,中文。
case-abbr: escape cases with half-width dots likeMr.,e.g..Mr.->Mr.
space-full-width-content: keep one space between half-width content and full-width content中文English中文->中文 English 中文
space-punctuation: keep no space between full-width punctuation and the content besides, keep one space between half-width punctuation and the content besides中文 , 中文->中文,中文
case-math-exp: overwrite cases with math expressions1+1=2->1 + 1 = 2
case-backslash: deal with the backslash specially to avoid unpredictable result这实质上和问题 \#1 是相同的
space-brackets: keep one space outside and no space inside a pair of brackets when it's half-width, keep no space inside or outside when it's full-widthspace-quotes: keep one space outside and no space inside a pair of brackets when it's half-width, keep no space inside or outside when it's full-widthcase-traditional: unify all quotes, as part of the translation conventions.a「b」c->a“b”c
case-datetime: deal with the date & time specially to avoid unpredictable result2020/01/02 01:20:30
case-datetime-zh: deal with the Chinese date & time format specially to avoid unpredictable result中文2020年1月1日0天0号0时0分00秒
case-ellipsis: deal with the continuous dots as ellipsis specially to avoid unpredictable result中文...中文...a...b...中文...中文...a...b...
case-html-entity: deal with the HTML entities specially to avoid unpredicutable result中文< & >中文
case-raw: deal with the inline code in markdown specially to avoid unpredictable result`Vue.nextTick`/`vm.$nextTick`
case-linebreak: deal with the linebreak (2 spaces at the end of a line) in markdown specially to avoid unpredictable result