README
docproc
An extensible document processor, suitable for human-friendly markup. Take it for a drive with your Markdown document of choice:
docproc path/to/your/file
Architecture Overview
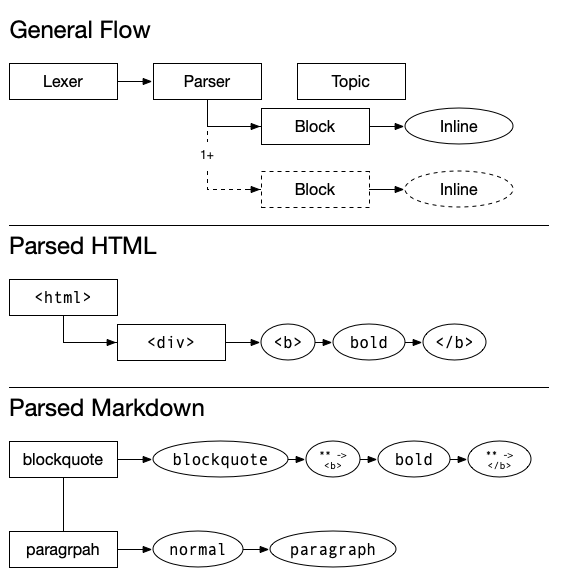
First, let's talk document structure. Human-readable docs are linear, and they're typically organized in groups (blocks). The blocks themselves contain inline data or sub-blocks.
## html blocks at different levels
<html>
<div><b>bold</b></div>
</html>
## markdown
> blockquote **bold**
normal paragraph
The basic approach to all solid document processors is that they use a lexer-parser pattern to break the doc down into its smallest part then sequentially put them back together (in our case, as blocks with inline text).
docproc isn't any different there. What docproc aims to do is create a pattern for configuring lexeme detection and block/inline handling. Once you get a sense for how these pieces fit it should make writing your own processor easy.
docproc makes no assumption about what you're trying to process, but it does come with a Markdown (CommonMark) plugin and DinoMark plugin, which enhances CommonMark with more dynamic processing capabilities.
How it Works (High Level)
Let's use the following snippet of Markdown as our reference:
> **blockquote**
paragraph _**bold italic**_
To start, we need to specify the following lexemes:
>**_\\n
Anything that isn't explicitly identified is grouped together and emitted as their own lexemes.
We'll also need to build two block handlers:
blockquoteHandlerwill only accept lines beginning with>. If there are 2 consecutive newlines, the blockquote handler is done.paragraphHandleraccepts anything. Like blockquote, it also terminates after 2 consecutive newlines.
Each instance of a block has its own handler instance.
Finally, we'll need to build two inline handlers:
boldHandlerstarts and stops**and allows embedded formattingitalicHandlerstarts and stops_and allows embedded formatting
Follow the Tokens
Let's trace how each token changes the state of the parser, starting at the block level:
>blockquoteHandlercan accept and is set as current handler
**,blockquote,**- all accepted by
blockquoteHandler
- all accepted by
\\n,\\n- blockquote done, no longer current handler
paragraphparagraphHandlercan accept and is set as current handler
_,**,bold,italic,**,_- all accepted by
paragraphHandler
- all accepted by
Pretty simple so far. Now let's look within the block and see what happens with the inline tokens. I'll use the paragraph handler:
_- matches an inline handler. it'll take all tokens until another
_, but since it allows embedding other formatting, it'll first defer the tokens to specific handlers if they exist - stack:
[italicHandler]
- matches an inline handler. it'll take all tokens until another
**- matches an inline handler, which nests and defers
- stack:
[italicHandler, boldHandler]
bold,italic- goes into
boldHandler
- goes into
**boldHandleris popped- stack:
[italicHandler]
_italicHandleris popped- stack:
[]
When you turn the document into a string, you get all the pieces back, assembled from fragments of HTML returned from the different handlers.
That's basically it! You can see it all put together in readme.example.ts
Take a deeper dive: