README
@vorlefan/xlsx
![]()

This is a experimental product. Only use it if you know what are you doing xD ctrl+shift+v
:books: Table of Contents
History Behind
I was working into a PaaS that requires to read a .xls|xlsx file and extract the data into a readable .json, in which will be sent for the database. Seeking around the web, I found the amazing 'mongo-xlsx', however, the data generated was a messy. So, I had the idea to create a package around the 'mongo-xlsx', in which I would use the other package 'string-similarity', to construct a better parse. In the end, it worked as I wanted and needed for the project. Then, I had decide to construct a 'better one' from the one I have built to share with everyone. Please, if you can contribute with pull-requests, do it. I guess that this package can be pretty useful for everyone to use :)
Packages
mongo-xlsx
string-similarity
@vorlefan/path
Install
With npm do:
npm install @vorlefan/xlsx
With yarn do:
yarn add @vorlefan/xlsx
Features
- Convert single xls|xlsx file into .json file
- Convert multiple xls|xlsx files into .json files
Usage
import * as XLSX from '@vorlefan/xlsx'
Documentation
xlsxConverter : Promise
import { xlsxConvertor } from '@vorlefan/xlsx'
interface XLSX_CONVETOR {
filepath: string | Function // the full filepath of the input file (.xls)
pathRoute?: PathRoute | null // If it is null, it will use the default, you can define one by using
// @vorlefan/path
routeName?: string // the route in which will save the output, * by default is main
callback?: Function | null // returns a function where the first paramater
// is the data generated, and the second is the error
}
xlsxConvertor({filepath, pathRoute = null, routeName = 'main', callback = null } : XLSX_CONVETOR)
// Example: at the main folder
xlsxConvertor({ filepath: './example.xls', }).then(console.log).catch(console.error)
// Or, if there is a 'example' folder at the 'main' folder
xlsxConvertor({ filepath: ({path_route}) => {
path_route.join('example', 'main')
return path_route.plug('example', 'example.xlsx')
}, routeName: 'example' })
XLSXPath : PathRoute
import { XLSXPath } from '@vorlefan/xlsx'
XLSXPath.get('main')
This is the default PathRoute using '@vorlefan/path'. It have by default a route with the 'main' folder of your project.
XLSX_GroupByValue : Function
import { XLSX_GroupByValue } from '@vorlefan/xlsx'
// arguments
interface GROUP_BY_VALUES {
search: string // search the key-value word by using similarity algorithim
node?: 'key' | 'value' // it will search on 'keys' or 'values'?
model: Array<object> // the model array that will be used (generad from xlsxConverter)
}
// return
interface GET_BY_KEY_OR_VALUE {
data: Array<any> | Record<any, any>
original_key: string
key: string
}
XLSX_GroupByValue({ search, node: 'key', model }: GROUP_BY_VALUES) : GET_BY_KEY_OR_VALUE
// Example:
const { XLSX_GroupByValue, XLSXPath } = require('@vorlefan/xlsx')
void (async function () {
const model = await XLSXPath.json()
.set('main')
.read({ filename: 'test.json' })
const data = XLSX_GroupByValue({
search: 'hashimoto',
node: 'value',
model,
})
await XLSXPath.json()
.set('main')
.store({ data, force: true, filename: `${data.key}.json` })
})()
Disclaimer
While it is true that it can be used in production, there are as well, several fields on the package that needs to be improved! If you want to use this package, my recommendations is: use it only for study or to contribute. If you want to use in production, be at your own risky xD
Example
By the sake of helping xD, take a look at the folder 'example' of this repository. May it help you, in case of using on production
Media
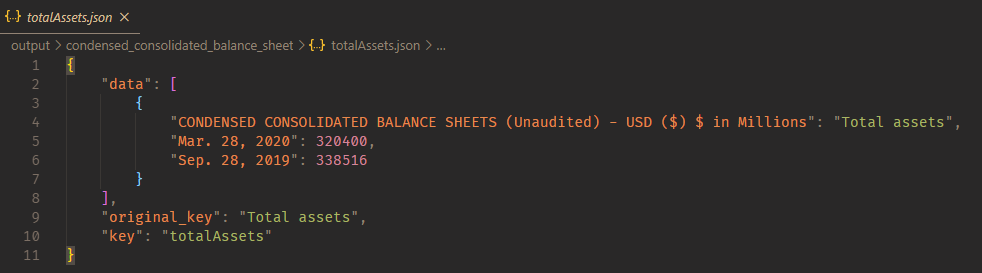
This media is from the example/intermediate
Media
From this Excel:
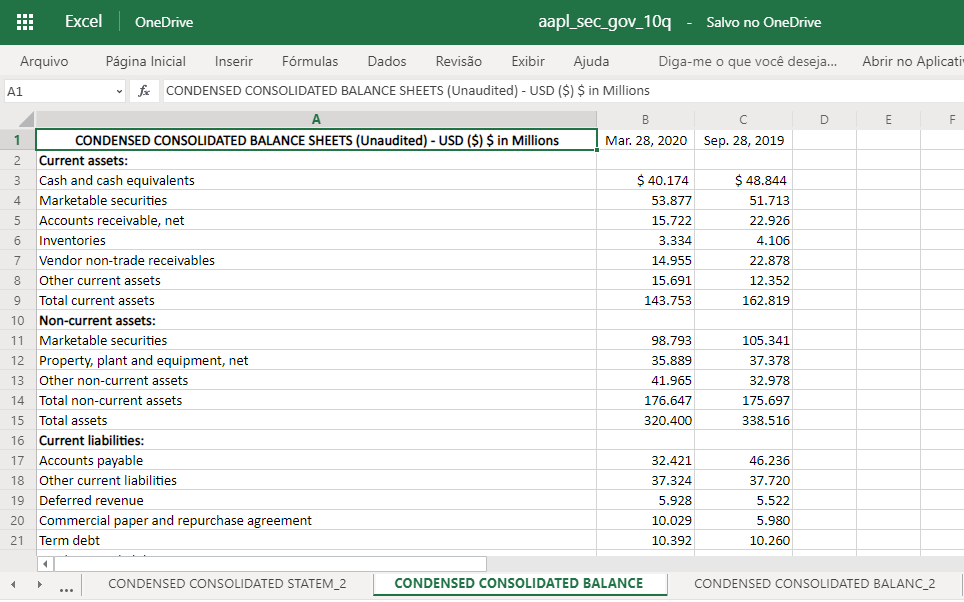
To this .json file:
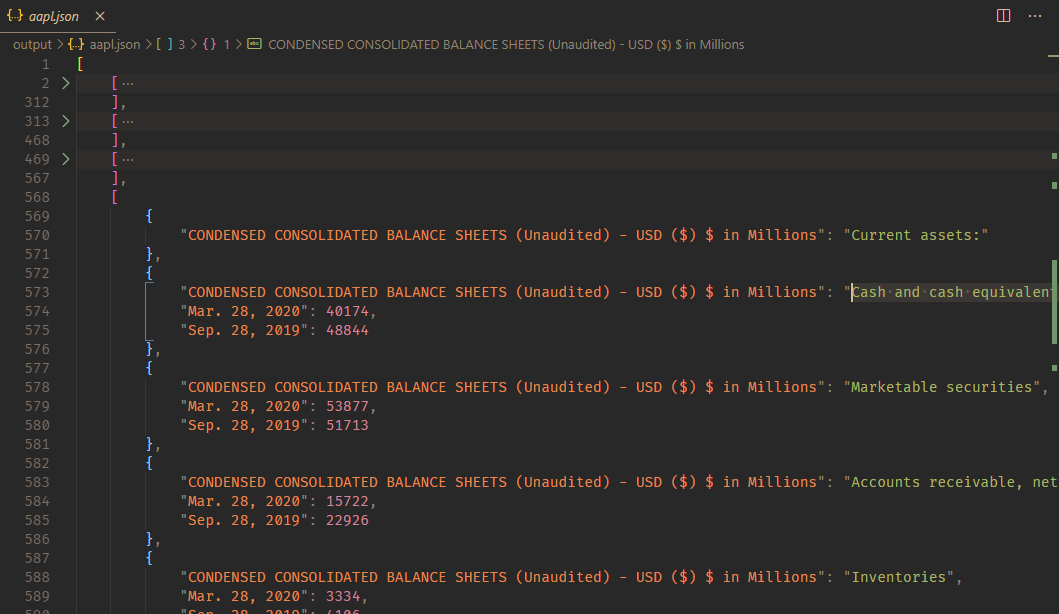
Then we gonna split, taking only the data from CONDENSED CONSOLIDATED BALANCE SHEETS (Unaudited):